
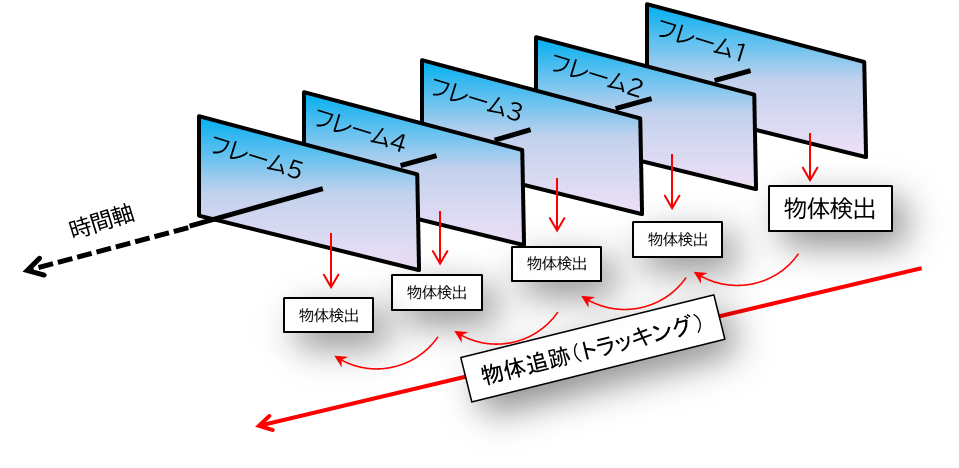
AI解析といっても、具体的にどのような処理を行っているのでしょうか。今回は、道路ラボのオリジナルアプリにおけるAI解析の基本的な仕組みを紹介します。撮影した動画から車両を検出・追跡する一連の流れを、1.フレーム分割+物体検出(YOLO) → 2.トラッキングの順に説明していきます。
1.フレームごとの画像に分割し物体検出
まず、動画で撮影した映像はフレーム(コマ)ごとに静止画に分割します。例えば1秒間に30フレームの動画であれば、1秒あたり30枚の画像が得られます。この場合、30fpsと表記されます。fpsはframe per second、つまりフレーム/秒ですね。
動画って、結局フレームの集まりで、パラパラ漫画ですから。このパラパラ漫画を一枚一枚取り出します。まずは、OpenCVという画像処理ライブラリを使ってフレームを1枚ずつ取り出します。
次に、各フレーム画像をAI(人工知能)に見てもらい、何が写っているかを判別させます。
具体的には、フレームの画像内のどこにどのような物体が存在するかを認識します。
この物体検出には、YOLO(ヨロ)アルゴリズムと呼ばれる手法を活用しています。YOLOは物体検出の分野で広く利用される先進的なディープラーニングモデルで、「You Only Look Once」(一度見るだけで全て検出する)の略称です。
名前の通り、画像を一度に解析して複数の物体を同時に検出・分類できるのが特徴です。
初代のYOLOv1(2015年)から最新のYOLOv8/v10(2024年時点)まで継続的に改良・進化が重ねられ、現在でも物体検出の代表格とされています。
YOLOは一枚の画像を見て、その中の複数の物体を同時検出し、それぞれに
・バウンディングボックス(位置)
・クラス(物体カテゴリ)
・確信度スコア
を出力します。
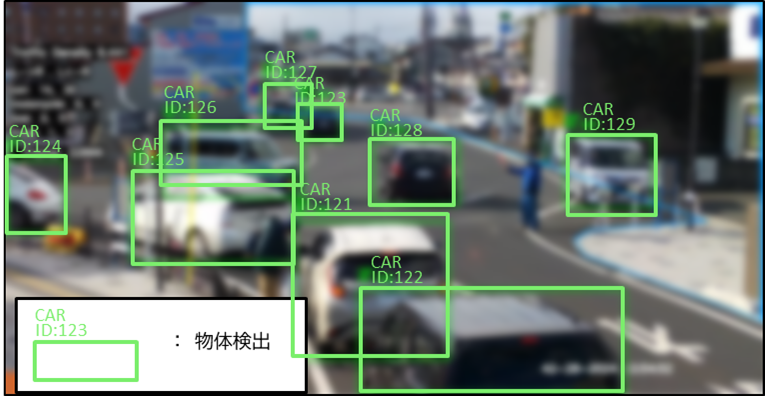
(※これは物体検出の様子です。実際はピントはあっていますが、ここではぼかしています。こういう動画や画像は個人情報と見なされますので、取扱いには最大限の注意をはらう必要があります。)
本題に戻りますが、動画は1秒間に多数のフレームがあるため、1秒間に30回もの物体検出を繰り返す必要がありますが、YOLOのような高速アルゴリズムならその厳しい条件にも対応可能です。
※ただし、全てのフレームを解析する必要が無い場合、つまり、数フレーム飛ばし(数フレーム間隔)で解析しても十分に車の動きが追える場合は、時間短縮のためフレームをスキップします。道路ラボオリジナルアプリではFrameSkipという数値で指定することが出来ます。
YOLOは無料!(オープンソース)
また、YOLOはオープンソースソフトウェアとして公開されており、完全無料で利用できます。道路ラボオリジナルアプリでも、この無料のYOLOライブラリを組み込んで、動画フレーム内の車両検出を実現しています。
ではYOLOはどのようにして物体を検出しているのでしょうか。
その核心はディープラーニングによる学習にあります。YOLOのモデルを作成する際には、数千~数万枚規模の画像を使って機械学習させ、「これが車だ」というパターンを学習させるそうです。そうすることで、新しい画像を与えれば一目見ただけでその中に車が写っているかどうか、いるならどこにいるかをモデルが推定できるようになります。YOLOは車だけでなく、学習データ次第で人や動物、信号機や標識など様々な物体を検出可能です。
そう、これは人間が学習する様子と酷似していませんか?人間も赤ちゃんの頃から、いろんなものを見てこれが車、これは人、これは動物、って覚えていくと思います。この学習の過程が、コンピューターで再現できるって、ちょっと不思議というか、すごい時代になってきましたね。
現在では、小売店舗での人物や商品検出、農業分野での作物や害獣検出、医療現場での異常検知など、小売から農業、医療まで非常に幅広い領域でYOLOが活用されています。このように応用範囲が広く性能の高いYOLOアルゴリズムを用いることで、道路映像から車両を効率良く検出できるのです。
2.物体追跡(トラッキング)による連続フレームの紐づけ
さて、1.により各フレームで車を検出できました。しかし、単にフレーム毎に独立して検出するだけでは、車両の動き(軌跡)を捉えることはできません。 例えば、1コマ目に写った車Aと2コマ目に写った車Bが同じ車なのか別の車なのかを判断しなければ、映像中でその車がどこへ移動したか追跡できないのです。
人間の目で物体の動きを見る場合も、連続した視覚情報の中で「同じ対象」を認識し続けることで初めて動きを把握できます。それと同じく、AIにも連続するフレーム間で同一の物体を紐づけて追跡する仕組みが必要になります。
この処理を「トラッキング(物体追跡)」と呼びます。
トラッキングでは、動画内で検出された各物体に番号(ID)を割り当て、フレームをまたいで同じIDの物体を追いかけることで移動経路を構築します。
道路ラボオリジナルアプリでは、この対応付けを行うトラッキング手法として「ハンガリアンアルゴリズム」方式と「DeepSORT」方式の2種類を選択できるようにしています。それぞれアプローチは異なりますが、いずれも入力は各フレームの検出された物体のバウンディングボックス情報で、出力として各物体に継続的なIDを付与していく点は共通です。
★ ハンガリアンアルゴリズム方式
物体同士の対応付けを最適化問題として解くアプローチです。各検出バウンディングボックス(tフレーム)と既存の追跡中オブジェクトの位置(t-1フレーム)との間にコスト(距離などの差異指標)を設定し、その総和が最小になる対応の組み合わせを計算によって求めます。この「コスト最小マッチング」を実現するためにハンガリアンアルゴリズムという解法が使われます。ハンガリアンアルゴリズムはもともと「誰にどの仕事を割り当てれば全体として最も効率的か」といった割り当て問題を高速に解くためのアルゴリズムで、物体追跡においては「あるフレームの物体を次のフレームのどの物体に対応させると全体の対応付けが最適か」を計算するのに適用されています。具体的には、各フレーム間でバウンディングボックスの位置の近さ(例えば重なり具合=IoU距離など)をコストとして算出し、それに基づいて前後フレームの物体を一対一でペアリングするような処理を行います。
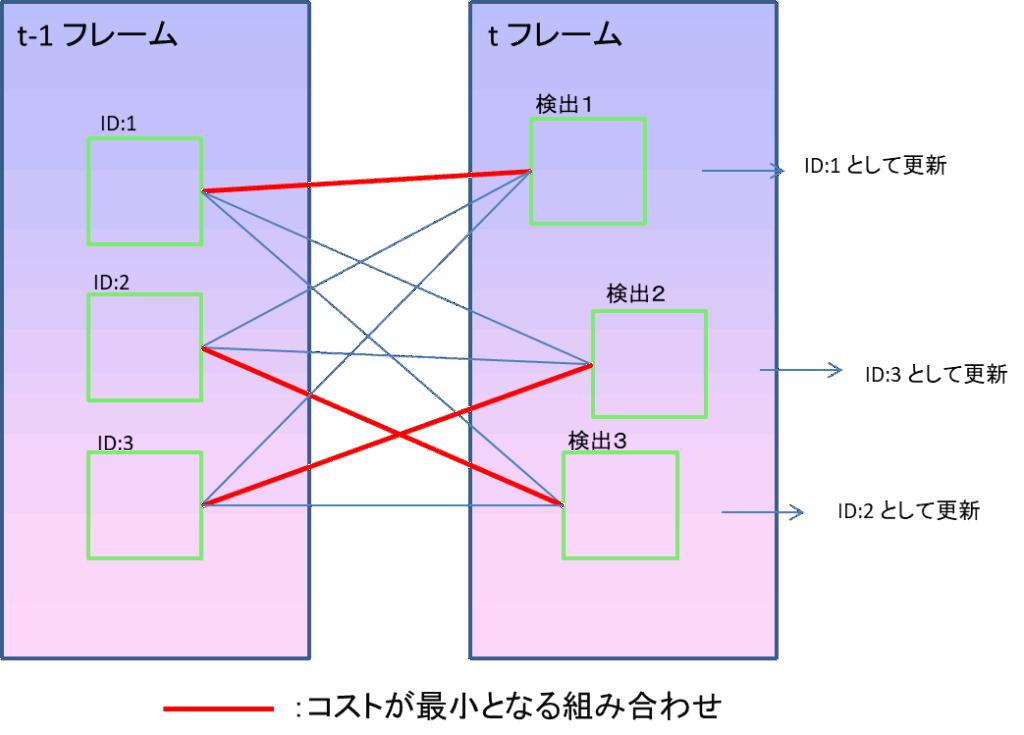
画像内でのバウンディングボックスの数が少ない時にはこちらの手法が確実です。
ただし、人ごみの中で多くのバウンディングボックスがあり、それが見え隠れするような場合、次のDeepSORT方式が有効になってきます。
★ DeepSORT(ディープソート)方式
上記の手法ではIDの付け違い(スイッチ)が起こりやすいという課題がありましたが、DeepSORTでは物体の外見特徴(Appearance)を活用することで対応付けの精度を向上させています。具体的には、各検出された物体画像からディープラーニングを用いて特徴ベクトル(外見特徴量)を抽出し、それを用いてフレーム間の物体の見た目の類似度を計算します。さらに、物体の移動予測にはカルマンフィルタ(物体の次フレーム位置を予測するアルゴリズム)を組み合わせ、移動の一貫性も考慮します。
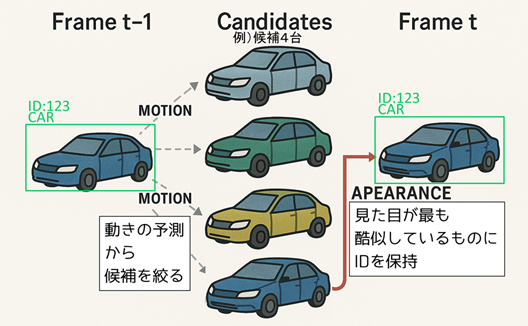
このように移動情報(MOTION)候補を絞って+見た目情報(APEARANCE)で最終マッチングすることで、単純に位置の近さだけで紐づけるよりも頑強になり、物体が一度隠れて再び現れた場合などでも同一個体を識別し続けやすいメリットがあります。その反面、ディープラーニングによる特徴抽出の計算コストが加わるため、シンプルな方法に比べると処理は重くなりますが、追跡の精度向上が期待できます。
以上の2手法のどちらを使うかは用途によって選択します。ハンガリアンアルゴリズムのみを用いた方法(SORTに類似)は実装が簡潔で高速なため、リアルタイム性を重視する場合に有利です。一方、DeepSORTは多少処理コストが増えても誤対応やID切替えを減らしたい場合に有効です。
なお、物体追跡の技術は他にも研究が進んでおり、
近年ではDeepSORTの後継である
・StrongSORT
(外観特徴抽出を強化し視点変化への適応を追加)
や、SORTの後継である
・ByteTrack
(低信頼の検出も活用するシンプルな手法でありながら非常に高い精度を達成)
といった新しい手法も登場しています。それぞれ精度向上やロバスト性強化の工夫が凝らされており、トラッキング分野は現在も活発に技術が進歩しています。
道路ラボオリジナルアプリではまだByteTrackなど、新しい手法は取り入れておりませんが、今後余裕があれば新しい技術にキャッチアップしていきたいと思います。(未定ですが。。)
以上、道路ラボ・オリジナルアプリにおけるAI解析の仕組みを簡単にご紹介しました。動画をフレームに分割してYOLOで高速物体検出し、さらにトラッキングで各車両の移動を追跡するという流れが本アプリの基本です。
この基本に、カラフルな線をどう跨ぐか、どのくらい滞留があるかなどをリアルタイムで数値として出力することで、交通状況が定量的に把握できるのです。
次回は、この道路ラボオリジナルAI解析ソフト自体の紹介と、実際にどのような出力結果が得られるのかについて、詳しくご紹介したいと思います。